
Project information
- Category: Deep Learning/ Reinforcement Learning
- Type: DQN - Deep Q-Network for Reinforcement Learning
- Client/Purpose: This experiment was aimed to implement and train a RL agent to successfully land the "Lunar Lander" in OpenAI gym
- Project date: March, 2021
- Project URL: github
Implementing a Reinforcement Learning DQN agent to solve the Lunar Lander
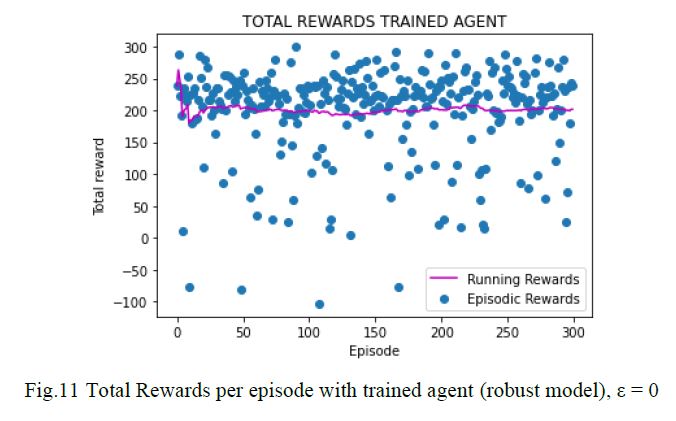
For the Lunar Lander environment provided in OpenAI Gym, the goal is to land a rocket in a landing pad which is at coordinates (0,0). This environment has an 8-dimensional state space. Six of those states are modeled as continuous variables, and two more as discrete, representing coordinates, speeds, angle and legs touching the ground. Four discrete actions are available: do nothing, fire left orientation engine, fire main engine, fire right orientation engine. The environment also provides different rewards. The episodes finishes when the lander crashes or comes to rest. The problem is considered solved when achieving a score of 200 points or higher on average over 100 consecutive runs.
The sequences of observations are assumed to terminate in a finite number of steps; hence, the system can be modeled as a MDP to which we can apply standard reinforcement learning methods.
Deep Q-network (DQN), is only one approach that can be applied to solving the environment combining a convolutional neural network with Q-learning to learn control policies, first applied to video games.
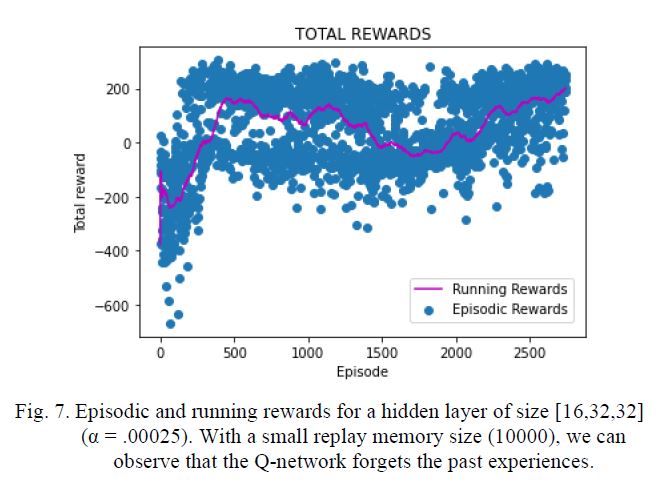
The experiments consisted of exploring variations and combinations on the following hyperparameters: number of hidden layers of the Q-network, learning rate, random and greedy steps for exploration and replay memory size.